
摘 要 传统犯罪率测算方法存在内容上的片面性、计量方法上的主观性、数据来源上的人为性等弊端。综合犯罪率是以法院刑事案件审理大样本为直接数据来源,对多个维度的刑事案件信息进行统计学降维处理而计算的犯罪率,是多个细分犯罪率以及从中提炼浓缩的主成分因子的综合。其测算方法实现了内容上的综合性、计算方法上的客观性和数据来源上的原始性三个突破。综合犯罪率的测算方法属于法学实证发现的工具理性范畴,为犯罪、刑法以及刑事政策研究拓展出一些新的知识推进场景:犯罪状况的评估与预测、刑事大样本数据信息的构造发现、犯罪与相邻社科现象之间关系的实证研究。四百七十万个样本的综合犯罪率测算结果发现,目前中国社会最突出的犯罪问题主要不是财产犯罪、暴力犯罪、人身犯罪,而是失信犯罪。此外,不能一般地说“经济越发达,犯罪问题就越严重”或者相反,不宜再将犯罪状况的“轻重”与刑事政策的“宽严”简单对应起来。
关键词 犯罪率 降维分析 主成分分析和因子分析法 失信犯罪 刑事政策
与血压、血脂、血糖相似,犯罪率是宏观社会健康状况的一种诊断指标。但是,无论对决策还是学术研究,犯罪率的作用都十分有限。不是因为这个指标不重要,而是因为其测算方法的科学性存疑,因而测算结果的精准度、可信度不高。本文主旨在于说明现有犯罪率测算方法的缺陷,并基于新的理论、方法改造传统犯罪率,讨论一种新型综合犯罪率的内涵及其应用。
一、犯罪率测算方法弊端及解决方案
(一)传统犯罪率测算方法的弊端
当代犯罪率测算可以追溯到19世纪被誉为“统计学之父”的比利时学者凯特勒于1835年出版的《论人及其才能的发展或论社会物理学》一书。他在关于1826年到1831年法国杀人案件的研究中发现,同一数字往往带着不可能被误解的规律性重复着,犯罪率的变化往往与一系列社会、自然因素有关。法国统计学家格雷也曾在《论法国的道德统计》一书中报告了他的研究结果。他对法国一些地区人身犯罪和财产犯罪的犯罪率进行分析,发现犯罪率的变化与某些地理因素有关。1930年美国国会通过决议授权联邦调查局于次年发布的第一份《统一犯罪报告》是官方犯罪统计的典型代表。我国学者也十分重视相关研究,很早就注意到公安犯罪统计失真问题,以及公开的犯罪数据十分有限等问题,并提出建立全国性统一的犯罪统计和被害调查制度的必要性问题。还有学者从犯罪数量、犯罪危害以及犯罪恐惧感等方面研究犯罪危害的测量方法。
犯罪率理应成为人们了解犯罪的范围、规模和规律并据此调整犯罪控制对策的重要指标。然而,一直以来,各式各样的犯罪率往往只能反映犯罪状况的某个片段或某个层次,不是过于概括而信息量有限,就是过于具体而无法全面、综合地反映犯罪问题。结果,真正影响决策的往往是一些极端个案。一般认为,犯罪率通常是指犯罪数与人口数之比。分母一般为每十万人口数。作为分子的犯罪数有犯罪案件数、犯罪人数、被害人数等不同形式。以犯罪案件为分子计量单位的犯罪率,即通常所说的发案率。发案率的计算有公安机关、检察机关、审判机关等不同统计口径,分别反映犯罪控制中不同环节的犯罪状况。但是,发案率无法反映一人犯罪与多人共同犯罪的不同,以及一人被害与多人被害的差异。以犯罪人为分子计量单位计算的犯罪率,称为人犯率。人犯率虽然对单独与共同犯罪的情形作出了区分,但和发案率一样,无法反映轻重不等的犯罪对社会的影响。在发案率和人犯率中,案与案之间、人与人之间是等值的。而且,发案率和人犯率都无法灵敏反映被害人的实际范围、规模、被害程度。所以,有学者特别看重被害率的价值。不过,被害率在数据获取、测算等方面也存在一定不确定性,难以全面实操。
除了发案率、人犯率和被害率之分,犯罪率还可分为总体犯罪率与单项犯罪率。前者是以犯罪案件或犯罪人的总量为分子计算的犯罪率。后者是以具体罪名、类罪等为分子计算的犯罪率,如故意杀人罪犯罪率、未成年人犯罪率、女性被害率,等等。如选取《中国法律年鉴》公布的全国公安机关刑事案件统计表中公布的立案数,除以《中国统计年鉴》中公布的当年全国总人数,计算出从1981年到2016年共36年的全国总体犯罪率。为了观察不同种类犯罪的数量规模,又可分别计算出故意杀人、故意伤害、抢劫、强奸、盗窃、诈骗等具体犯罪的犯罪率。单项犯罪率的好处是在不同程度上弥补了发案率或人犯率信息量损失过大的弊端,缺点是只能从某个片面反映犯罪状况,顾此失彼。此外,笔者还曾将犯罪率分为毛被害率、毛加害率、重罪被害率、重罪加害率四种,目的是体现犯罪率计算的精细化。不过,其中的重罪概念还是比较粗略,未能对不同的重罪加以区分。
其实,犯罪率测算还不能不考虑犯罪定义的变化。从空间看,不同国家的刑法规定不同,犯罪圈大小不同,其犯罪率就不具有可比性。从时间上看,一国的刑法也在不断修订。醉驾入刑前后的犯罪率也不宜拿来直接对比。还有,从加害可能性的维度看,犯罪率的分母是被简化为十万的总人口数,而不是具有刑事责任能力者的总人口数。因此,人口结构明显不同的两个时空,其犯罪率的比较也掩盖了单位人口中可能触犯刑法的总人口中犯罪数量的差异。如果从被害可能性的维度看,犯罪率只是相对数,如果相对数不变,不等于绝对数也不变。而绝对数的消长对每个可能的被害人来说,被害的概率实际上也有所不同。现有犯罪率就不能直接反映出这些区别。所以,还要和总量指标结合起来综合评价一个社会的犯罪状况。最后,犯罪率的计算依据只是已知犯罪的数量,无法将犯罪暗数计入分子,因而无法反映犯罪的实际范围、规模和数量。
总之,各种片面的犯罪率使任何负责任的决策者都不大会盲目相信其测算结果。而可靠的测算结果源自可靠的测算方法,现有犯罪率的片面性及各种的不可靠性源自其测算方法的简单片面。
(二)犯罪率数据源于人工填报
科学的犯罪率测算,首先要有数据来源上的保障。而现有多数犯罪率测算的数据来源,一般来自公安机关、检察机关、法院的各种人工填报数据。人工填报数据不仅可能出现笔误,而且可能受到不当利益驱动的影响。因为作为一种负面统计指标,犯罪率往往被视为犯罪控制工作的不足。特别是如果犯罪控制工作直接或间接与法治营商环境、投资环境挂钩,甚至列入干部绩效评价的范围,次年填报的犯罪率数据就难免会产生人为干预。为从源头上解决犯罪率测算的客观性和可持续性问题,我们需要一种无须人工填报也能反映犯罪实际的数据来源。当然,所谓无须人工填报,是指人工无法直接填报、涂改犯罪率分子上的数据信息,如案件数、人犯数、被害人数、财产损失数等数据。事实上,构成犯罪率分子上的各种数据说到底也离不开人力所为,如举报、作证、鉴定、立案调查、起诉、审理、辩护乃至执行等各个环节都是人的活动。只要人力所为不可能直接制造、掩盖或修改构成犯罪率分子的数据,就可以大体满足犯罪率数据来源的客观性要求。
(三)犯罪率测算方法的技术瓶颈
片面是全面的基础,细分是综合的前提。但是,如果缺乏科学的综合方法,就无法将各种量纲不同、维度各异的变量信息整合起来,形成犯罪现象的完整描述。遗憾的是,目前尚无一种成熟的综合测算方法被用于犯罪率研究。法学研究中近似的尝试是方兴未艾的法治指数评估。所用的综合方法是研究者根据自己对法治的基本理解,设置多个、多级指标,然后采用所谓德尔菲法为各个指标人为赋予大小不等的权重,最后对权重不同的各个指标进行汇总计算。根据这种指标体系进行测算,可以实现不同时空下法治水平的可比性。如果借用这种方法,也可能对不同维度的犯罪数据信息进行综合。比如,分别对重罪、轻罪、罪案、罪人赋予不同的权重系数,然后进行数据汇总,实现不同时空犯罪状况的定量比较。
但是,这种综合测算方法难免人为赋权的主观性。即对某个指标或维度赋予多大的权重,完全取决于研究者对该指标重要性的理解。不说同一研究者的理解此一时彼一时,不同的研究者更可能对同一指标的重要性持有不同理解。结果,就难免出现按照某个评估团队的测算,某地的法治指数排名领先,而换了一个研究团队,同一个评估对象的排名却落到最后的窘境。这种主观色彩较重的测算方法不仅可能导致同一指标体系内的系统性误差,而且,依据不同指标体系进行测算的结果之间也失去了可比性,甚至使得法治指数的评估显得很不严肃。所以,就连积极倡导法治指数评估的专家学者都承认专家赋权法未必可靠。
应当承认,人工赋权并非在任何情形下都不可取。在自上而下的演绎逻辑中,需要按照某种既定标准建模以区分不同个案时,人工赋权是体现专业标准的较好手段。但是,犯罪率的测算过程应该是对已然事实信息自下而上进行经验归纳的过程。演绎过程希望回答的是“应当如何”的问题,即评估对象与应然标准有多大差距。而归纳过程希望回答的是“实际上如何”的问题,不存在预设的犯罪率应该多高或多低的评判标准。事实上,犯罪是一定客观规律的作用结果,把犯罪率的高低与犯罪控制工作的绩效直接挂钩,本身就是不科学的。硬要在犯罪率测算中对不同指标人工赋权,并据此以人工填报数据对各地犯罪状况进行评估,就相当于开卷考试。甚至,被评估者可能根据需要对考试结果进行调整,其测算结果的可信度可想而知。如此看来,选用人工赋权方法对各种具体犯罪指标进行综合的方法并不可取。
(四)犯罪率测算的理念误区
正确理解犯罪率与刑事政策的关系,是坚持犯罪率测算客观性的保障。一般认为,犯罪率的高低是决定刑事政策宽严的事实依据和理由。犯罪增多了,刑事政策理应严一些。反之,犯罪减少了,刑事政策就可以适当放宽一些。其实,这是关于犯罪率与刑事政策之间关系的一种危险的误解。首先,刑事政策的宽严,除了与犯罪的多少有关,还是犯罪控制主体自身多种因素影响的结果。刘邦废除秦法,犯罪圈里只剩下杀人、伤人及盗三个罪名,显然不是因为当时犯罪减少了,而是与汉初统治者的统治策略高度相关。同理,犯罪数量规模的消长变化,也不完全取决于刑罚的轻重或刑事政策的宽严。18世纪中后期遍及欧洲的刑法改革、废除死刑、刑罚轻缓化等变化,并没有收到犯罪大幅减少的预期效果。犯罪是多种原因的复杂结果,犯罪状况与刑事政策之间的关联,并没有想象中那么紧密。相反,不适当地夸大犯罪与刑事政策之间的关联关系,反而会以牺牲犯罪率的客观性为代价,用犯罪率的所谓变化论证或支持刑事政策的调整。甚至,以犯罪率的消长为由,掩盖调整刑事政策的真实原因。所以说,简单理解犯罪率与刑事政策之间的关系是十分危险的。
关于刑事政策与犯罪率之间关系的简单化理解,与犯罪率尴尬的学科定位有关。作为犯罪数量与人口数量之比,犯罪率基本上是一个社会学、犯罪学概念。逻辑上,与之相应的对策面,就应该是社会、经济、文化、教育、福利等社会管理、控制手段。而实际上,我国虽有综合治理一说,但刑事立法、刑事司法、刑事政策才是我国犯罪治理的基本方式。而适合刑事法治的犯罪率概念尚未得到系统研究,这就形成了社会学意义上的犯罪率概念与刑事法治实践相脱节的局面。为改变这种局面,与其坐等社会经济文化的全方位犯罪预防措施,不如先行探索能与刑事法治实践相对接的犯罪率概念。而适合刑事法治实践的犯罪率概念,就应设法将有关刑法规则、概念嵌入犯罪率的测算。这个意义上的犯罪率也将更多地反哺刑事法治,成为沟通刑事政策与刑法适用效果之间的信息桥梁。
(五)综合犯罪率概念及其测算方法之提倡
目前,我国尚无官方发布的全面犯罪率。为满足社会对公开、科学的犯罪率数据的需要,本研究提出一种综合犯罪率的概念。所谓综合犯罪率,是指以法院刑事案件审理大样本为直接数据来源,对多个维度的刑事案件信息进行统计学降维处理而计算的犯罪率。为摒弃传统犯罪率测算方法在内容上的片面性、在计量方法上的主观性、在数据来源上的人为性等弊端,综合犯罪率测算的科学性主要体现为内容上的综合性、计量方法上的客观性和数据来源上的原始性三个特征。
内容上的综合性体现在,综合犯罪率是多种刑事案件信息的全面反映:既包含罪案信息,也包含罪人信息,还包含罪行信息;既反映加害方面的信息,也反映被害方面的信息;既体现重罪对社会的影响,也体现轻罪的危害;既可以从中观察具体常见个罪的信息,还可以让人了解各种犯罪概括性的数据。而且,综合犯罪率不是分别报告这些犯罪信息,而是对这些数据信息进行综合汇算后,用尽可能少的量化结果显示犯罪的基本状况。之所以可能实现专业内容上的综合性,是因为综合犯罪率测算选用的是统计学上的降维分析方法。
降维统计方法的引入,使得综合犯罪率对多个变量的综合无须任何人为赋权。按照降维分析的原理,综合犯罪率的测算将采用主成分分析和因子分析法,对多个原始变量指标进行降维处理,用几个主成分代表原有变量的信息,并形成测算对象犯罪状况的最终量化表达。主成分分析和因子分析是十分成熟的统计学方法,在自然科学、经济学、社会学中已有广泛应用。在犯罪研究中,有人曾用因子分析方法研究过四川省的相关数据,尚未见到全国性犯罪研究中的应用。如果能成功用于犯罪现象的描述,不仅是法学、犯罪学的一次创新,也是统计学方法应用领域的有益拓展。
数据来源的原始性体现在,综合犯罪率的测算将尝试以法院刑事审判大样本为直接数据来源,放弃依靠人工填报获取数据。很明显,这样做的目的就是排除人工填报的人为性、可操作性,从源头上解决测算的主观性问题。同时,也能客观反映刑事法治实践的过程和结果,为刑事法治的科学化服务。难点是如何将自然语言写成的裁判文书转换成格式化可计量的数据变量。不过,对今天的计算机信息技术而言,裁判文书自然语言的数据转换早已不是问题。真正需要讨论的问题是,据此计算的犯罪率所反映的,只是经由司法机关发现、证实、认定并判处相应刑罚的犯罪,而无法将犯罪暗数计入在内。这个意义上的犯罪率的本质是什么?测算这种犯罪率的意义何在?
第一,在犯罪定义学看来,世界上原本不存在任何裸的犯罪。犯罪都是犯罪化的结果。如果没有人们出于一定需要,依据一定程序,将某种行为定义为犯罪,就无所谓犯罪的存在。所以,重要的不是什么实际上是犯罪,而是什么被定义为犯罪。刑事司法就是将一定案件事实定义(判决)为犯罪、赋予犯罪意义的过程和结果。从这个意义上说,以审判信息为数据来源计算的综合犯罪率所反映的,本质上不是作为认识对象的犯罪,而是作为价值实践结果的犯罪。这个意义上的犯罪已经不仅仅限于触犯刑法的行为本身,而是这些行为与相应规则及其适用的综合体。综合犯罪率是这种综合体的数量表达。
第二,把一定行为规定为犯罪的立法活动和把一定行为依法判决为犯罪的司法活动都是犯罪化实践。然而,刑事立法只是将应当被犯罪化的行为规定为犯罪。只有当刑法被具体适用时,犯罪化才由应然转化为实然。而综合犯罪率就是这种实然犯罪化过程与结果的反映。这个意义上的犯罪率的分子,既不能还原为绝对独立于犯罪定义者的纯粹的所谓犯罪现象,也不能还原为完全独立于犯罪定义对象的刑法规定及其适用。综合犯罪率所描述的犯罪,是犯罪定义对象与定义者之间互动的过程与结果。它不是简单地告诉我们这个世界发生了多少应当被称作犯罪的行为,而是告诉我们现行犯罪定义系统(立法、司法)的运作实际上生产出多少叫作犯罪的行为。如果说司法案例是法治的细胞,那么,综合犯罪率就是在法治机体的细胞层面研究犯罪。事实上,也不可能有人准确测算出犯罪暗数的实际规模范围,然后告诉我们到底发生了多少犯罪。
第三,既然犯罪率反映的不仅仅是危害社会的加害行为,同时还是刑法适用活动的描述,那么,犯罪率的高低既说明犯罪的多少与轻重,同时也说明刑法适用范围的大小与宽严。一个相对较高的犯罪率,不是说明犯罪较为严重,就是说明刑法适用过严过厉。这样,用综合犯罪率评价不同地方的犯罪控制效果,就可能形成一种良性驱动:在犯罪本身的严重性同等的情形下,如果对刑事犯罪量刑偏重或过重,犯罪率就会显示较高。只有量刑适度,才不至于展现一个较高的犯罪率。借此提高各地审判机关适度量刑的积极性,是控制犯罪控制的一种理性设计。同理,当某地法院对同种犯罪的量刑轻重与全国法院相应犯罪的量刑水平相当,但综合犯罪率显示高于或低于其他地方,则说明犯罪本身的确较重或较轻。促进社会经济合理地投入惩戒资源,也是综合犯罪率的意义所在。
应该承认,目前已公开的法院数据并不完整,我们不知道到底有多少司法文书未被公开。因此,如果根据已公开的数据计算犯罪率,理论上可能存在一定误差。但是,公开的裁判文书不完整,不等于不存在完整的裁判文书。再说,本研究旨在探索一种新测算方法,不必以全样本为实验材料。况且,只要严格按照科学抽样的规则进行样本选取,目前已公开的裁判文书已经能够满足许多具体研究的需要,其结果仍是有意义的。
二、实验设计与结果
看一种测算方法是否科学有效,最好的办法就是进行实验检验。综合犯罪率测算能否真的矫正传统犯罪率的弊端,可能带来哪些未知的问题,都需要实验数据结果出来后才能回答。
(一)样本
实验样本来自中国裁判文书网,选取其中2015年至2021年11月全部公开的刑事案件共4969446个。其中,2015年759860个,占比15.3%;2016年790148个,占比15.9%;2017年857177个,占比17.2%;2018年866643个,占比17.4%;2019年860055个,占比17.3%;2020年657310个,占比13.2%;2021年178253个,占比3.6%。考虑到2021年尚未上传其余案件,应将其剔除,研究样本的时间跨度为2015年至2020年六个年度的全部上网刑事案件共4791193个。目前,中国裁判文书网的数据来自各地各级法院上传的裁判文书。而出于保密、隐私保护等各种考虑,尚有一定数量的裁判文书未能公开。但据保守估计,已公开数据应该已经过半。因此,本测算结果虽然方法论意义相对更明显,仍在一定程度上反映了这个时期我国的犯罪实际。
(二)分析单位
由于一案可能由多人实施,一人可能犯有数罪,本研究样本的分析单位确定为“人―罪”。即若一案一人一罪,则为一条记录。若一案二人每人一罪,则为两条记录。若一案二人每人犯两罪,则为四条记录。分析单位的前后一贯性,既是罪刑关系分析的逻辑保障,也是综合犯罪率测算真实性的前提。实际上,不论“案”还是“人”,都不是直接影响犯罪被害的最小分析单位。综合犯罪率研究的测算从刑罚裁量的直接对象即“人―罪”出发,优于一般犯罪率分子的分析单位非案即人的做法,与刑事法治的对接更为精准、科学。
(三)原始变量
初步观察四百多万个样本,可以从中提取几百个变量。但其中多数变量不是样本过少就是与犯罪率研究无关。为实现犯罪率测算的综合性,实验首先对样本进行了频次分析,对高发案率的样本按法定刑的不同逐一分类,以此确定综合分析的原始变量。结果,提取了以下变量作为降维分析的前提:共同犯罪、累犯、无期及以上刑罚、致被害人死亡、三年以下盗窃、三到十年盗窃、十年以上盗窃、三年以下伤害、三到十年伤害、十年以上伤害、三年以下交通肇事、三到七年交通肇事、七年以上交通肇事、三年以下诈骗、三到十年诈骗、十年以上诈骗、三到十年抢劫、十年以上抢劫、三年以下妨害公务、三到十年杀人、十年以上杀人、三到七年贩毒、七年以上贩毒、三年以下非法拘禁、三到十年非法拘禁、十年以上非法拘禁、三年以下非法吸收公众存款、三到十年非法吸收公众存款、三到十年强奸、十年以上强奸、三年以下抢夺、三到十年抢夺、十年以上抢夺、五年以下职务侵占、五年以上职务侵占、三年以下掩饰隐瞒犯罪所得、三到七年掩饰隐瞒犯罪所得、三年以下开设赌场、三到十年开设赌场、三年以下聚众斗殴、三到十年聚众斗殴、三年以下虚开增值税发票、三到十年虚开增值税发票、十年以上虚开增值税发票、三年以下毁坏财物、三到七年毁坏财物、危险驾驶拘役缓刑、危险驾驶拘役无缓刑共48个变量。
之所以将这48个变量纳入初步观察的范围,首先是因为除了危险驾驶罪的法定刑为拘役以外,有期徒刑是绝大部分犯罪最常见的法律适用结果。第二,经初步观察,上述犯罪在四百七十多万个样本中的发生率较高,能够大体上代表全国范围内的基本犯罪状况。第三,上述犯罪的类型分布也分别代表了人身犯罪、财产犯罪、暴力犯罪等各种犯罪,可以体现研究对象的综合性。最后,根据某罪法定刑幅度对具体罪名进行细分,有助于提高样本的颗粒度,既满足综合性要求又尽可能减少信息量的损失。
(四)计量方法
由于研究涉及多个变量,应选用多元分析工具进行研究。同时,由于研究涉及的多个变量并非某个既定因变量的自变量,显然不宜采用多元线性回归分析,而应采用降维分析的主成分分析和因子分析方法进行研究。
降维分析的基本思想是在不损失大量信息前提下,把多因素问题转化成较少因素的问题,以降低问题的维数,用较少的变量代替原有多个变量进行量化分析。主成分分析和因子分析就是两种主要的降维分析方法。其中,因子分析的原理是,根据多个基础变量之间相关性的大小进行分组,组内变量之间的相关性较高以实现其同质性,而组间变量之间的相关性较低以实现异质性。其实质是从多个显在变量提炼少数几个潜在因子的归纳过程。例如,有学者运用主成分分析方法对西部地区各省、区创新能力进行综合评价;有学者利用主成分分析法对包括陕西在内的全国内地30个省、市、自治区科技竞争力进行排序,分析陕西在科技发展水平方面与全国整体水平及与其他发达省市的差距;还有的学者采用主成分分析法对13种力学类中文期刊进行分析和排名,认为主成分分析法可以解决期刊综合评价中指标的相关性和权重选取等问题。然而,该法在法学研究中尚无成熟先例。
本研究所面对的问题是在尽可能不损失太多原始信息的前提下,如何将裁判文书中多个维度的数据信息整合、简化、提炼为尽可能少的计量结果。与常见的犯罪原因多元分析相比,共性是都面对多个维度的数据信息而属于多元分析。不同之处在于,在犯罪原因分析中,有一个需要给出解释的目标变量,即因变量,如案件数量、犯罪人的数量、被害损失的数量、是否再犯,等等。然后,用社会、经济、文化、个体、家庭、心理等多个维度的数据作为自变量,观察分析这些多元的自变量与一个连续的或者二分的因变量之间的关系。所用的分析工具多为多元线性回归分析或者罗杰斯特回归分析。其中,多个自变量之间的独立性越高越好。否则就会出现所谓“多重共线性”问题。与此不同,当下的犯罪率研究,不是用多个自变量解释一个已知的因变量,而是从多个变量中提炼、浓缩共性,前提是多个变量之间存在共性。降维分析中的主成分分析法和因子分析法恰好适合解决此类问题。不过,作为第一次尝试,采用降维分析方法研究犯罪率出来的结果应该不再是每十万人口中的全部或某类案件数或人数,而是多个具体细分犯罪率浓缩提炼后形成的某个值。这个意义上的所谓犯罪率能否为人所接受,大概需要一个过程。
(五)建立降维分析数据库
进行降维分析还需确定测评对象。综合犯罪率的测评对象,既可以是空间,也可以是时间。如果以空间为测评对象,就可以对不同省市、地市、区县的综合犯罪率进行静态分布分析。如果以时间为测评对象,就可以对不同年份、季度或月份的综合犯罪率进行动态趋势分析。本文尝试以31个省市为对象进行综合犯罪率测算。为此,首先建立以省市、共同犯罪的人―罪总量、三年以下盗窃的人―罪总量、三到十年故意杀人罪的人―罪总量、十年以上故意杀人罪的人―罪总量等字段的数据库。然后,根据各省市2015年至2020年六个年度平均人口数,计算出各省市的细分犯罪率,即各省市某种具体犯罪的“人―罪”数量对每十万人口的比率,共得到48个细分犯罪率,如某省的共同犯罪率、累犯率、三年以下盗窃率、三到十年故意杀人率,等等。经初步观察,某些细分犯罪率的样本量过低,进行全国性比较没有意义。最终,决定保留24个细分犯罪率作为降维分析的原始变量。
(六)降维分析的适用性检验
并非所有多变量数据都可以进行降维分析。因此,需要以31个省市为样本,以上述24个细分犯罪率为原始变量,运行降维分析进行KMO检验。统计学认为,KMO值大于等于0.5时,进行因子分析才是适当的,该值越接近1越好。据此,运行降维分析过程后发现,排除三到十年盗窃率、十年以上抢劫率、三到七年贩毒率、七年以上贩毒率、三年以下掩饰隐瞒犯罪所得率、危险驾驶拘役缓刑率和危险驾驶拘役无缓刑率等7个变量,才能满足KMO检验的要求。因此,实验最终保留以下17个细分犯罪率进入因子分析,作为计算综合犯罪率的基础变量:人身伤害致死率、无期及以上刑罚适用率、共同犯罪率、累犯率、三年以下盗窃率、三年以下伤害率、三到十年伤害率、十年以上伤害率、三年以下诈骗率、三到十年诈骗率、三到十年抢劫率、妨害公务率、三到十年杀人率、十年以上杀人率、三年以下非吸率、三到十年非吸率、三到七年掩饰隐瞒犯罪所得率。据此计算的KMO值为0.688,巴特利特球形度检验的显著值为0.000,均符合因子分析的适用性要求。
最终构成综合犯罪率分析的这17个基础变量体现了综合性要求:涵盖了加害和被害因素(人身伤害致死率);罪行及罪人因素(共同犯罪率、累犯率);轻罪与重罪因素(无期及以上刑罚适用率);财产犯罪与暴力犯罪;普通犯罪与涉众犯罪(非法吸收公众存款犯罪率);民对民的犯罪与民对官的犯罪(妨害公务犯罪率)。最终获得的综合犯罪率,将是集合这些要素的综合表达。需要说明的是,本研究用17个细分犯罪率测算综合犯罪率,并不意味着综合犯罪率只能由这17个细分犯罪率构成。综合犯罪率由哪些原始变量构成,并不是固定的,在很大程度上取决于样本质量及其内在结构。样本不同,满足KMO和巴特利特球形度检验的变量组合就不同,所提取出来的主成分因子就不同。综合犯罪率的测算过程本身,就是在寻找哪些原始细分犯罪率更能客观反映该时空下犯罪实际的探索过程。
(七)提取有效反映犯罪状况的主成分因子
用17个方面的细分犯罪率说明31个省市的犯罪状况还是过于细碎,尚需进一步归纳、浓缩。从表1中可见,运行降维分析过程后,程序从17个基础变量中提取出4个主成分因子。根据降维分析原理,这4个主成分因子之间相互独立,但每个主成分因子内部各个变量之间高度相关,共同说明该主成分因子的经验含义。
具体来看,在主成分因子1当中,三年以下及三年到十年的非法吸收公众存款犯罪率、妨害公务犯罪率、三年以下及三到十年诈骗犯罪率有较高的载荷,分别为0.901、0.910、0.907、0.633、0.689。其中,非法吸收公众存款犯罪更接近欺骗类犯罪,妨害公务犯罪以暴力犯罪的形式折射出社会公信力方面的问题,诈骗犯罪更是人际之间信赖关系的滥用,它们都与“骗”和“信”有关。因此,主成分因子1可以称为失信因子,主要代表失信相关的犯罪。在主成分因子2中,载荷最高的几个变量依次为累犯率、三年以下盗窃率、共同犯罪率、三到十年抢劫率、三到七年掩饰隐瞒犯罪所得犯罪率,分别为0.939、0.898、0.847、0.626、0.525。其共性是传统财产犯罪,可以称为传统侵财罪因子。在主成分因子3中,载荷最高的几个变量依次为三到十年及十年以上伤害犯罪率、无期及以上刑罚适用率、三到十年抢劫犯罪率、十年以上故意杀人犯罪率,分别为0.895、0.825、0.799、0.606、0.517。其共性为较严重的暴力犯罪,可称为暴力犯罪因子。在主成分因子4中,载荷最高的几个变量依次为三到十年故意杀人犯罪率、人身伤害致死率、十年以上故意杀人犯罪率、三年以下伤害犯罪率,分别为0.813、0.786、0.689、0.599。其共性为人身暴力侵害,可称为人身犯罪因子。这4个主成分因子的提取,最大限度保留了基础变量的信息。同时,用4类犯罪代表这个时期内我国犯罪状况的基本结构,能帮助人们更容易综合地理解犯罪实际。
表1 提取的主成分因子
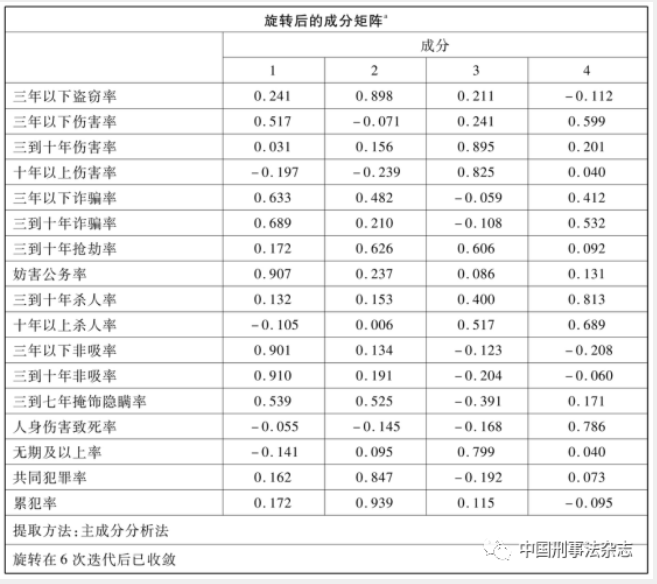
有趣的是,并非所有降维分析提取出来的主成分因子都在专业上具有易解释性。而本文研究结果显示,除了第三和第四个因子经验上可以合并以外,所提取出来的几个主成分因子之间的确相互独立,因子内部共性明显,分别从失信、侵财和暴力等方面给出这个时期内我国各地的犯罪状况的量化描述。这反过来说明选用降维分析法研究综合犯罪率是可行的。
(八)计算综合犯罪率
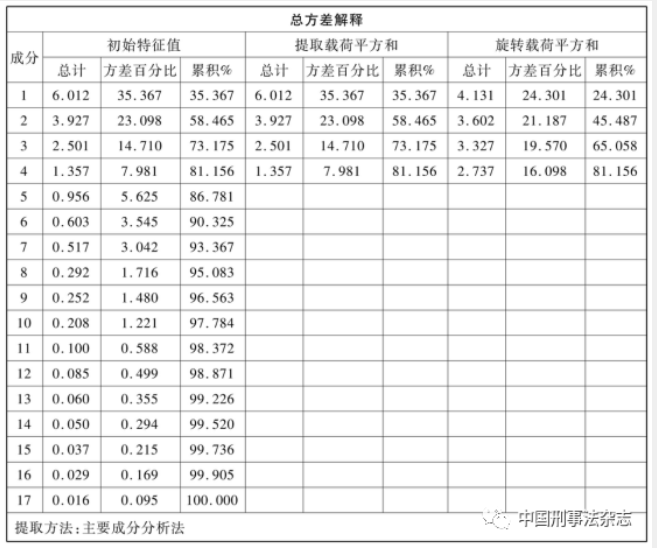
完成了上述多次归纳、浓缩以后,现在可以根据提取的主成分因子的贡献率大小计算综合犯罪率。从表2可见,因子1的贡献率为35.367%,因子2的贡献率为23.098%,因子3的贡献率为14.710%,因子4的贡献率为7.981%。四个主成分因子的累积贡献率为81.156%。
应当承认,提取主成分过程中损失的原始信息将近19%。这可能说明了原始数据本身的复杂程度。为了更好地解释主成分因子,系统又对其贡献率进行旋转,旋转后得到表2中“旋转载荷平方和方差百分比”。据此,便可生成综合犯罪率模型:
综合犯罪率=因子1×24.301+因子2×21.187+因子3×19.570+因子4×16.098
表2 综合犯罪率的基本构成
因为每个因子的贡献率是系统根据因子旋转后的实际数据信息生成的,所以根据该模型,无须任何人工赋权,即可算出每个样本的综合犯罪率得分、每个主成分因子的得分以及所有得分的排序。其中,每个省市的综合犯罪率得分可以理解为该省市四个主成分因子对其犯罪状况的综合反映。每个省市的综合犯罪率总分不同,构成总分的四个主成分因子的得分也不相同。
表3的第一列为31个省市样本的数字代码。之所以不直接列出省份名称,是因为本研究无法获取各地审判信息的全样本。作为一种方法论探索,即使给出各省市的综合犯罪率排序其实际意义也不确定。第二列是运行上述综合犯罪率模型后得到的各地综合犯罪率原始得分,分数越大,说明综合犯罪率越高。综合犯罪率为正值的,说明高于全国平均水平,综合犯罪率为负值的,说明低于全国平均水平。第三列是不同样本综合犯罪率高低的排序。原始得分越高,排序的位置越靠前。例如,第14号省份的综合犯罪率得分为80.61,在31个样本中最高,因而排序第1。第28号省份的综合犯罪率得分为负值,即-83.89,大大低于平均水平,总体排序第31。同理,第六列、第七列分别列示了因子1即失信因子的原始得分及其排序位置。原始得分越高,该因子的排序就越靠前。例如,第25号省份的该主成分因子得分2.94,在所有样本中得分最高,排序最靠前,说明该省份的失信相关犯罪在全国最为突出。其余因子原始变量及排序依此类推。还有,表3只列示了31个省市的综合犯罪率。若要了解全国的综合犯罪率,就需要以全国各个年度数据为样本进行计算,然后对全国不同年度的综合犯罪率进行比较。不过,根据降维分析对样本与变量之间比例关系的要求,样本个数应明显大于变量个数。而全面公开法院数据只是近几年的事情,所以,全国动态综合犯罪率的测算条件还不成熟。
要说明的是,综合犯罪率既然是多种具体犯罪数量与相应法律适用的综合,就必须假定相同的犯罪得到了相同的法律适用。否则,某地的某个细分犯罪率与彼地的同一个细分犯罪率之间就不具有可比性。事实上,我们只能假定如此,因为司法实践中同案异判不可避免。这就需要某个衡量同案同判水平的指标,供人们比较不同地方综合犯罪率高低时作为参考。可是,如何测算不同地方司法实践中量刑的均衡性水平,尚无公认的成熟方法。因此,考虑到有期徒刑是适用率最高的常见法律后果,本研究暂且用有期徒刑适用的方差水平作为一个比较综合犯罪率时的补充性指标。
表3省市综合犯罪率及结构
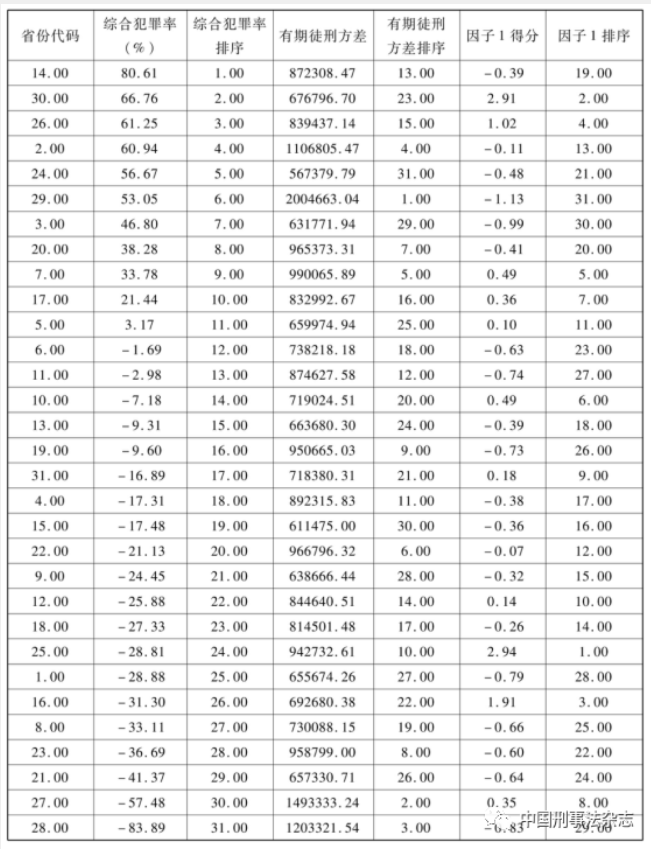
方差是用来度量随机变量与其平均水平之间离散程度的统计指标,样本的方差越大,说明其离散程度越大,方差越小,说明样本数值距离均值的距离越近。例如,对同样一组犯罪案件,A组法官作出了一年、两年、三年、四年、五年、六年、七年、八年、九年有期徒刑共九种量刑结果,而B组法官作出了三个四年、三个五年、三个六年有期徒刑共三种量刑结果。这两组量刑的均值都是五年有期徒刑,但是,A组量刑结果的方差为7.5,B组量刑结果的方差仅为0.75。这说明,A组量刑结果的方差是B组的十倍,离散程度远远大于B组,“离谱”的程度较大。对这个差异,考虑到量刑实践的大量经验观察,我们有理由认为,A组量刑同案异判的可能性很可能大于B组。表3的第四列列示了每个省份有期徒刑的方差数据,第五列列示了各省市有期徒刑方差的排序。不难看出,方差最小即量刑结果集中趋势最为明显的是第24号省份,方差最大即量刑结果离散趋势最为明显的是第29号省份。
用有期徒刑的方差近似地代表各地法院量刑的离散程度,是综合犯罪率可信度相对合理性的补充说明,因而也是综合犯罪率的一种矫正机制。其原理是,量刑的离散程度越小,实际数据越接近平均值,集中趋势越明显,基于具体犯罪量刑结果计算的细分犯罪率之间才越具有可比性。按照这种机制,在综合犯罪率同等的情形下,量刑方差越小,综合犯罪率的测算结果越可信。于是理论上便有四种可能:第一,综合犯罪率很低,且量刑方差也很小,应该是刑事法治的最佳状态;第二,综合犯罪率很高,且量刑方差也很大,应该是刑事法治的最差状态;第三,综合犯罪率比较低,量刑方差却较大,应该是刑事法治的较好状态;第四,综合犯罪率比较高,量刑方差却较小,应该是刑事法治的较差状态。需要注意的是,从最佳、较好、较差到最差之间不存在绝对界限,最好把综合犯罪率、量刑离散程度、四个主成分因子得分结合起来综合评估某地犯罪状况,这应该也是综合犯罪率所谓“综合”的应有之义。
(九)结论:综合犯罪率测算法实现了技术和理论上的突破
以全国范围31个省市样本2015年至2020年六个年度的四百七十多万个“人―罪”数据进行降维分析所得到的综合犯罪率,基本上革除了以往犯罪率测算方法在内容上的片面性、计量方法上的主观性、数据来源上的人为性等三大弊端。一方面,综合犯罪率测算方法在技术上的突破可以概括为,以法院刑事审判大样本为直接数据来源――排除犯罪率测算结果的人为操纵的可能;以多维度的常见刑事案件数据信息为分析对象――弥补传统犯罪率测算方法的片面性不足;以主成分分析和因子分析等降维统计分析方法为量化工具――摈弃法治评估常用的人为赋权汇总方法;以有期徒刑的量刑方差对综合犯罪率加以补充――丰富了综合观察理解犯罪状况的视角。另一方面,综合犯罪率测算方法在理论上对传统犯罪率概念的突破在于,综合犯罪率已经不再将所谓犯罪从犯罪化过程中抽离出来孤立地测算犯罪的数量、密度,而是把犯罪作为犯罪化的结果看待,具有更强的理论意义和刑事法治实践价值。
总之,综合犯罪率中的所谓综合,就是多个细分犯罪率及主成分因子的综合、定性与定量的综合、犯罪本身与犯罪化过程的综合。用全国六个年度的大样本数据进行实证检验,证明此测算方法大体上是可行的。建议最高政法机关在具有足够影响力的学术机构协助下采用此种测算方法对所掌握的全样本数据进行测算,使综合犯罪率的测算、提供、公开与应用成为国家行为。在此基础上,对各地刑事法治实践进行有针对性的宏观指导。果如此,既可以满足原始信息保密性要求,又可以使其效能最大化,积极推动具有中国特色刑事法治的科学化进程。
三、实证发现的新场景
作为法学知识推进的重要形式,法学实证发现是运用实证研究的方法,描述、解释大量法律事实材料背后理论与实际之间的关系。综合犯罪率的测算方法是法学实证发现的工具理性范畴,具有很强的实用价值。其实际应用为犯罪、刑法以及刑事政策研究拓展出一些新的知识推进场景,包括犯罪状况的评估与预测、刑事大样本数据信息的类型化与结构重组、犯罪与相邻社科现象之间关系的实证研究。
(一)犯罪状况的评估与预测
一种新的测算方法如果不能与当下的普遍实践相对接,其意义便很有限。目前,各类法治评估、营商环境评估、高校排名、期刊排名是某种尴尬的存在。一方面,地方政府或高校领导明知这些排名的主观成分较大,因而不必十分在乎;另一方面,在缺乏其他评估方法与之竞争的情况下,这些评估又事实上对地方政府、大学及期刊构成无形的影响。客观上,有些所谓评估还会产生羞辱末位甚至不当交易等负面效果。为摆脱这种种的无奈,高公信力的测评手段呼之欲出。用综合犯罪率对不同地方的犯罪状况进行比较,能在较大程度上排除评估标准和过程的主观性和人工干预。即使事先公开评估模型,评估对象也不大可能通过底层数据的人为造假操控评估结果。客观性和抗人为干扰性,是综合犯罪率测算方法独特的优势所在。
基于综合犯罪率的测算方法对地方犯罪状况进行评估,可以分别从其总分、主成分因子、初始因子三个层次上实现不同地方犯罪状况的比较。从表3就可以看出,综合犯罪率的测算既可以实现样本(省市)之间综合犯罪率的比较,也可以根据其主成分结构具体说明某个省市为什么综合犯罪率较高或较低。例如,综合犯罪率排名第一的第14号样本,之所以综合犯罪率如此之高,是因为其失信因子排序第6,其传统侵财因子排序第13,其暴力犯罪因子排序第6,其人身犯罪因子排序全国第1。根据综合犯罪率模型中各个因子的客观权重综合计算,结果当然排序最高。相比之下,综合犯罪率排名最后的第28号样本,之所以综合犯罪率最低,可以解释为其失信因子排序第22,其传统侵财因子排序第29,其暴力犯罪因子排序第26,其人身犯罪因子排序全国第28。根据综合犯罪率模型中各个因子的客观权重综合计算,结果自然排序最低。实际观察也证实,这一结果与两地真实情形基本吻合,说明综合犯罪率的测算方法具有一定的解析力。在实际应用中,还可以按照距离综合犯罪率均值水平的远近,将各省份综合犯罪率的实际得分依次分为“很高”“较高”“一般”“较低”“很低”等组别,以便于综合犯罪率抽象数值的理解。
此外,我们还可以借助原始数据库对样本进行更细化的观察比较,从17个原始变量的维度对31个省市样本的犯罪状况进行比对,为各地犯罪控制整改实践提供更具体的建议。例如,根据测算,全国范围内共同犯罪率最高的是第15号样本,累犯率最高的是第30号样本,无期及以上刑罚适用率最高的是第29号样本,人身伤害致死率最高的是第21号样本,十年以上故意杀人犯罪率最高的是第14号样本,三到十年非法吸收公众存款犯罪率最高的是第24号样本,妨害公务犯罪率最高的是第2号样本,等等。借助综合犯罪率的测算方法对犯罪问题进行地方性分析,具有很强的实践意义。这种分析可以帮助地方有关单位清楚看到本地与其他地方在哪些方面存在哪些差距,为了实现精准犯罪控制,如何采取针对性措施有效缩小这些差距。
与犯罪率测算的空间场景相关,犯罪率测算的另一个场景是犯罪的动态描述与趋势预测。具体方法是,把样本的分析单位由省市(地区)改为年度、季度或月份,其他变量设计和测算方法不变。这样,就可以实现综合犯罪率前后时间的动态比较,描绘出全国或某地犯罪的动态轨迹,进而基于往期犯罪发展规律预测未来的发展趋势,为宏观刑事政策的调整提供事实依据。静态与动态实证分析结果相结合,是研究犯罪问题的最佳路径。根据这种动静结合的方法对犯罪问题的地方性、规律性进行时空分析,可以有针对性地指导刑事法治实践,贯彻宏观刑事政策,形成政法工作的新机制。
(二)刑事大样本数据信息的构造发现
综合犯罪率的测算过程是个先“打碎”再“提纯”的过程。“打碎”就是根据具体罪名的法定刑、样本的人口信息把粗颗粒的“人―罪”数据进一步进行细化,形成细分犯罪率。“提纯”就是对打碎后细颗粒度的原始细分犯罪率进行降维分析,对有效信息重新归纳、分组,找出主成分因子,形成新的类型化构造。“打碎”的质量如何决定了“提纯”能否有新的发现。如果犯罪事实信息细分得不够,某些有用的信息就会隐藏在原料中,无法被有效提纯出来。“提纯”其实就是构造发现,即从看似杂乱无章的细碎信息中发现犯罪现象的规律、构造,让某些肉眼看不见的关系显现出来。本研究从最前期的计算机读取几百万份刑事判决书,生成四百七十万个“人―罪”数据的上千个原始字段,到逐步筛选出48个、24个、17个细分犯罪率,就是个“打碎”的过程。运行降维分析过程进行主成分分析及因子分析,发现失信犯罪因子等四个主成分因子及各自的贡献率,就是个“提纯”的过程。没有这个过程,我们只知道犯罪大致上可以还原为暴力、偷窃和欺骗三类原始形态。这次的“提纯”过程才让我们发现,失信犯罪是当下我国犯罪问题中的首要问题。尽管本研究旨在新的犯罪率测算方法研究,但其实验所用四百七十多万个“人―罪”数据已属于超大样本,其结果应当比较接近实际。
理论上,犯罪现象可以还原为三种原生形式:暴力、偷窃和欺骗。这三种形式的犯罪,是犯罪现象的基本形态。即使演化为各种非典型形态,也可以从中发现三类原始犯罪的基因。例如,间谍犯罪或资助恐怖活动犯罪,都可以归结为间接的暴力。抗税、遗弃等行为可以理解为不作为的暴力犯罪。贪污、挪用公款、私分国有资产、徇私舞弊不征、少征税款以及知识产权犯罪等,都是偷窃的现代形式。除了各种典型的诈骗犯罪以外,像诬告陷害、诽谤、煽动、伪劣产品、假药、拐骗等行为,也应还原为欺骗类犯罪。以往的研究已经证明,这三类典型的犯罪,在现行刑法罪名体系中占绝大部分。现在,综合犯罪率的实证研究第一次证实,三类原生犯罪不仅是立法上罪名体系的主体部分,也代表了现实中犯罪现象的基本结构。可以认为,理论、立法、犯罪现实,三者相互印证,证实了犯罪现象的三元构造。不同的只是,理论上关于犯罪形态的三元素描述,只是定性分析,并不知道其实际分布。立法上三类犯罪的存在方式,与法定刑的轻重高度相关:暴力犯罪的刑罚最重,偷窃类犯罪次之,欺骗类犯罪相对最轻。而综合犯罪率的实证研究发现,三类犯罪的贡献率不同:传统侵财犯罪、暴力―人身犯罪并非当今中国最突出的犯罪问题,目前中国社会最突出的犯罪问题是与失信相关的犯罪。证据是,“失信因子”对综合犯罪率的贡献率最高,“传统侵财犯罪因子”的贡献率次之,“暴力―人身侵害因子”的贡献率相对更小。这个发现为进一步研究其原因、对策提供了一个事实起点。至少,对各类犯罪无差别地笼统分配刑法资源,未必明智。
根据这个“打碎―提纯”的思路,我们还可以根据不同的规则、理论,计算出各种各样的特定综合犯罪率,灵活服务于各种研究目的。具体方法是主动选用某类特定犯罪的原始数据作为计算其综合犯罪率的初始数据,其他方法都不变,就可以实现各种角度的构造发现,专注某类犯罪问题的研究。比如,以青少年犯罪涉及的全部罪名为原始变量,计算全国或某地某时段青少年犯罪的综合犯罪率。然后,将其结果用于人口、教育、家庭、健康、心理等要素之间关系的研究。尤其是,重新犯罪(再犯)是个传统且常新的犯罪研究课题。现实中,大量犯罪其实只是少数重新犯罪的犯罪人所为。现在,如果利用综合犯罪率的测算方法,以我国重新犯罪的全样本为数据来源进行降维分析以发现其特有规律并制定相应对策,应该是一项具有重大理论价值和实践意义的研究。
关于综合犯罪率测算的应用价值,可能面对的一种批评是,脱离国际通行的犯罪率测算方法另搞一套,会失去国际可比性。笔者认为,这种担心有些多余。因为,各国刑法犯罪圈的内容、范围差异很大,加之传统犯罪率测算方法的各种片面性,概括、笼统的犯罪率测算本来就没多大可比性。如果综合犯罪率测算法具有一定的先进性,反倒可能实现中外某类犯罪案件之间的深度比较。况且,所谓国际通行做法为什么永远都是绝对正确、不可撼动的判断标准呢?
(三)法学与其他社会科学的对话
综合犯罪率的测算还可能为犯罪与刑法研究走出法学而与其他社会科学研究对话创造条件。一方面,回顾以往研究,人们从社会、经济、文化、心理、生物等许多视角研究犯罪现象,积累了大量解释犯罪的自变量。但是,作为因变量,过于简单片面的犯罪率测算方法,已经成为犯罪研究深入推进的障碍。现在,有了综合犯罪率,情况将有所不同。例如,从表4可见,以2014年31个省市的居民恩格尔系数、工资性收入、财产性收入以及食品烟酒等消费支出为自变量,以2015年至2020年31个省市综合犯罪率为因变量进行回归分析,结果发现:居民工资性收入的高低与综合犯罪率之间呈反比关系,工资性收入越高的地方,综合犯罪率越低,而工资性收入越低的地方,综合犯罪率越高。与此不同,居民的财产净收入与综合犯罪率之间呈正相关关系,财产净收入越高的地方,综合犯罪率也随之越高,财产性收入越低的地方,其综合犯罪率也随之越低。居民收入结构为什么会与犯罪状况之间具有这种关联,是个十分有趣的问题。
表4综合犯罪率的经济分析
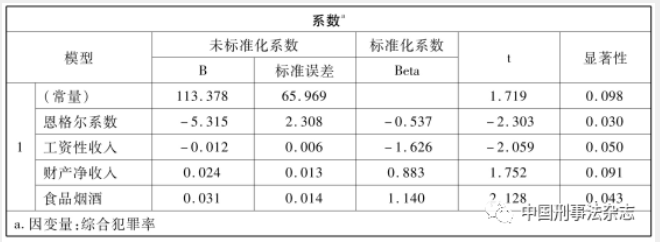
表4中,恩格尔系数的高低与综合犯罪率之间呈反比关系。恩格尔系数越高,意味着居民日常基本生存需要的支出在收入中的占比越高,说明经济发展程度越低。这个反比关系说明,越贫困的地方,综合犯罪率越低;越富裕的地方,综合犯罪率就越高。但是,综合犯罪率却与各地食品烟酒的消费支出呈正相关关系,食品烟酒消费越高的地方,犯罪率越高,反之则犯罪率越低。这两个数据之间看似矛盾,其实,烟酒并非维持生存的必需食物。所以,恩格尔系数与犯罪率呈反比,与食品烟酒与犯罪率呈正比,恰恰从两个角度共同说明经济发展与犯罪之间呈正相关关系。
另一方面,在传统犯罪学研究中,犯罪率的高低往往是因变量。研究需要回答的是影响这一因变量变化消长会受哪些自变量的影响,是哪些原因造成的结果。其实,当我们将综合犯罪率还原为若干主成分因子时就不难发现,这些主成分因子还可以作为自变量进入研究,观察其对某个或某些因变量的影响。例如,以上述四个犯罪主成分因子为自变量,以全国31个省市2015年至2021年六个年度各省平均人均GDP为因变量,运行一个多元线性回归过程,就会发现犯罪与经济发展之间存在很强的相关关系。分析结果表明,这个回归过程的R2高达0.702,说明四个主成分的共同作用可以在犯罪与经济的关系范围内解释70.2%的GDP的变化。
表5 综合犯罪率主成分因子与人均GDP的关系
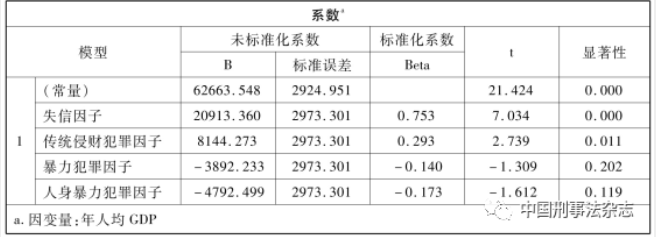
从表5可见,失信因子与人均GDP之间的关系最强、最显著,Beta值高达0.753。传统侵财犯罪的影响也很明显,Beta值为0.293。与此不同,暴力人身犯罪因子与人均GDP之间呈负相关关系,且不够显著。这表明,如果以人均GDP为经济发展程度的一个指标,那么,经济发展程度越高的地方,失信犯罪问题也相应地越突出,同时,传统侵财类犯罪问题也越严重,而暴力―人身犯罪越少。同理,经济发展程度越低的地方,更突出的问题将是暴力―人身犯罪,而非失信犯罪或传统侵财犯罪。这意味着,不能一般地说,经济越发展,犯罪问题就越严重或者相反,而应具体分析犯罪问题与经济发展之间的特定关联关系。此外,在法律现象范围内,观察综合犯罪率上下游的各种关系,还可能有许多关系值得深入挖掘。
总之,不论作为因变量还是自变量,综合犯罪率的测算打通了犯罪研究与其他社会科学研究或其他部门法研究之间的通道。在这个视野下,那种把犯罪状况的“轻重”与刑事政策的“宽严”简单对应起来的看法,已经显得有些过时了。

